Exercice: détection des changements de végétation
Aperçu
Dans cet exercice, nous allons créer un cahier pour détecter les changements de végétation. Pour comparer les changements, nous avons besoin de données de deux époques différentes: un ensemble de données plus ancien et un ensemble de données plus récent.
Le cahier comprendra les étapes suivantes:
Charger les données Landsat 8
Calculer un indice de végétation pour les données chargées
Divisez les données de l’indice de végétation en deux, en fonction du moment où les données ont été collectées - une moitié plus ancienne et une moitié plus récente
Calculez le composite moyen pour chaque moitié; et
Comparez les moyennes les plus anciennes et les plus récentes pour vérifier les changements de végétation.
À la fin de cet exercice, vous aurez effectué une analyse de la végétation qui peut être utilisée pour rendre compte des changements dans la zone sélectionnée.
Configurer le notebook
Dans votre dossier Training, créez un nouveau notebook Python 3. Nommez-le Végétation_exercice.ipynb. Pour plus d’instructions sur la création d’un nouveau notebook, consultez les instructions de la session 2.
Charger des packages et des fonctions
Dans la première cellule, tapez le code suivant, puis exécutez la cellule pour importer les dépendances Python nécessaires.
import matplotlib.pyplot as plt
%matplotlib inline
import datacube
from deafrica_tools.datahandling import load_ard
from deafrica_tools.plotting import display_map
from deafrica_tools.bandindices import calculate_indices
Note
À partir de juin 2021, le paquet deafrica_tools a remplacé l’importation de fichiers dépréciée sys.path.append('../Scripts'). Pour plus d’informations sur deafrica_tools, visitez la documentation du module DE Africa Tools””.
Dans cet exercice, nous importons une nouvelle fonction, calculer_indices.
Au lieu de calculer des indices de bande tels que NDVI en définissant une formule, nous pouvons faire appel à des calculs d’indices prédéfinis dans le bac à sable. calculate_indices contient les définitions de plus d’une douzaine d’indices différents, du NDVI à l’indice de sol nu (BSI) en passant par l’indice d’humidité des houppes (TCW), et peut les appliquer à votre jeu de données.
Utiliser cette fonction pour sélectionner l’indice que l’on souhaite peut sembler être un effort considérable. Cependant, il y a quelques avantages à utiliser la fonction calculate_indices, comme nous allons le voir dans cet exercice.
Réduit les risques d’erreur lors de la saisie de la formule, puisqu’ils sont déjà définis dans le script
calculate_indices- c’est génial pour les formules plus compliquéesComparez différents résultats d’index sans définir manuellement de nombreuses formules différentes
Réduisez le nombre de définitions que vous devez taper - par exemple, il n’y a pas besoin de
red=ounir=comme nous l’avons utilisé dans la Session 4
Nous utiliserons calculer_indices après avoir chargé le jeu de données.
Connectez-vous au datacube
Entrez le code suivant et exécutez la cellule pour créer notre objet dc, qui donne accès au datacube.
dc = datacube.Datacube(app="Vegetation_exercise")
Sélectionnez la zone d’intérêt
Nous devons sélectionner un domaine d’intérêt. Certaines zones à vérifier pour les changements de végétation comprennent les sites miniers, où il pourrait y avoir de la végétation, ou les cultures, où des changements saisonniers de verdure de la végétation se produisent.
Auparavant, nous avons fourni une plage de longitude et une plage de latitude. Cependant, il est plus courant de définir un point central et de fournir un tampon autour de lui.
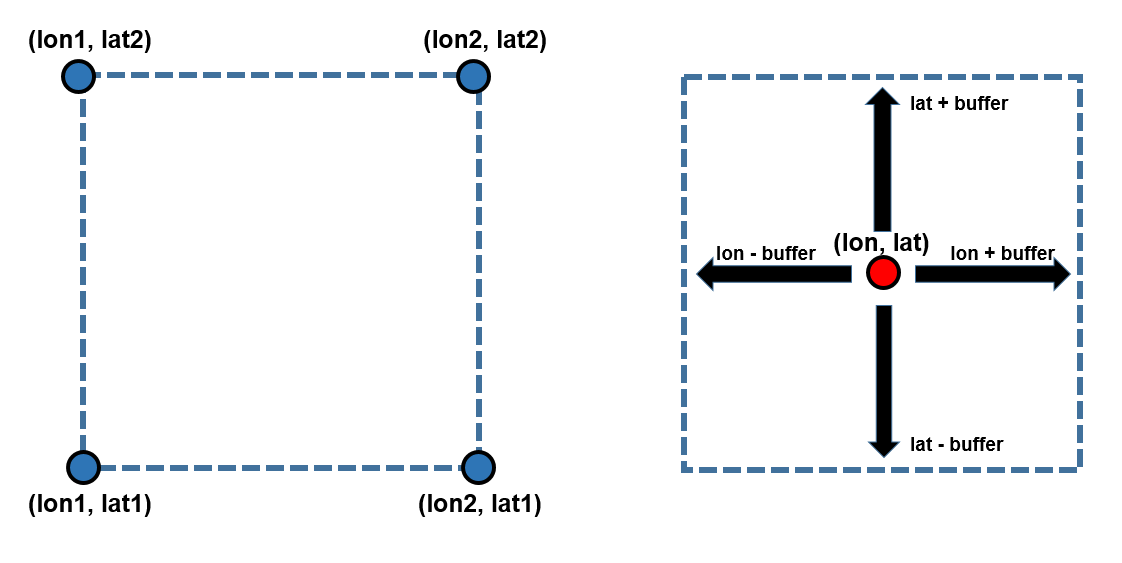
Nous avons précédemment utilisé la méthode * ``x=(lon1, lon2), y=(lat1, lat2)`` (à gauche) pour définir notre zone d’intérêt. Dans cet exercice, nous allons utiliser la méthode de la zone tampon (à droite). L’avantage est que vous pouvez définir une zone tampon à utiliser dans les quatre directions, et qu’il est beaucoup plus facile d’explorer différentes zones en modifiant le point central et/ou la largeur de la zone tampon.
Nous sélectionnerons une zone autour d’un point central. Entrez le code suivant et exécutez la cellule pour sélectionner une zone et une période d’intérêt. Les paramètres sont:
latitude: La latitude au centre de votre zone d’intérêt.longitude: La longitude au centre de votre zone d’intérêt.buffer: Le nombre de degrés à charger autour de la latitude et de la longitude centrales.time: La plage de dates à analyser. Pour des résultats raisonnables, la plage doit s’étendre sur au moins deux ans afin d’éviter de détecter les changements saisonniers.time_baseline: La date à laquelle il faut diviser l’ensemble des données en deux échantillons qui ne se chevauchent pas. Pour cet exercice, nous choisissons une date à mi-chemin de notre plage de temps. Sa valeur ici,'2015-12-31', est à mi-chemin entre'2013-01-01'et'2018-12-31'- la plage de temps danstime. Nos deux périodes seront donc de 2013 à 2015, et de 2016 à 2018.
Dans la cellule suivante, entrez le code suivant, puis exécutez-le pour sélectionner une zone.
# Define the area of interest
latitude = 0.02
longitude = 35.425
buffer = 0.1
# Combine central lat,lon with buffer to get area of interest
lat_range = (latitude-buffer, latitude+buffer)
lon_range = (longitude-buffer, longitude+buffer)
# Set the range of dates for the complete sample
time = ('2013-01-01', '2018-12-01')
# Set the date to separate the data into two samples for comparison
time_baseline = '2015-12-31'
Dans la cellule suivante, entrez le code suivant, puis exécutez-le pour afficher la zone sur une carte. Puisque nous avons défini notre zone en utilisant les variables lon_range et lat_range, nous pouvons les utiliser au lieu de retaper (latitude-buffer, latitude+buffer) et (longitude-buffer, longitude+buffer).
display_map(x=lon_range, y=lat_range)
Charger des données
Puisque nous voulons examiner une plage de temps plus longue, les données Landsat 8 conviennent. Dans la nouvelle cellule ci-dessous, entrez le code suivant, puis exécutez-le pour charger les données Landsat 8.
Remarquez que lat_range, lon_range et time ont tous été définis dans la cellule précédente, nous pouvons donc les utiliser comme variables ici.
Note
Si vous n’êtes pas sûr de l’endroit où nous avons défini lat_range, lon_range et time, faites défiler jusqu’à la cellule précédente et cherchez les lignes commençant par lat_range = ..., lon_range = ... et time = ....
landsat_ds = load_ard(
dc=dc,
products=["ls8_sr"],
lat=lat_range,
lon=lon_range,
time=time,
output_crs="EPSG:6933",
resolution=(-30, 30),
align=(15, 15),
group_by='solar_day',
measurements=['nir', 'red', 'blue'],
min_gooddata=0.7)
Le résultat de l’exécution de la fonction load_ard() devrait inclure une déclaration disant Loading 46 time steps (« chargement de 46 pas de temps »).
Note
À partir de juin 2021, les données Landsat de DE Africa ont été mises à niveau vers la collection 2. Les noms des cubes de données ont été mis à jour en « lls5_sr », « lls7_sr » et « lls8_sr ». Les conventions de dénomination obsolètes telles que « ls8_usgs_sr_scene » ne fonctionneront plus. Pour plus d’informations sur Landsat Collection 2, visitez la documentation DE Africa Landsat.
Calculer les indices
Nous devons maintenant calculer un indice de végétation.
Jusqu’à présent, nous avons utilisé le NDVI, qui utilise le rapport des bandes rouge et proche infrarouge (NIR) pour identifier la végétation verte vivante. La formule est:
Cette fois, nous utiliserons l’indice de végétation amélioré (EVI). EVI utilise les bandes rouge, proche infrarouge (NIR) et bleue pour identifier la végétation, et est particulièrement sensible aux régions à forte biomasse, c’est pourquoi il peut être supérieur au NDVI. La formule pour EVI est plus compliquée que NDVI car elle utilise trois bandes différentes et des constantes de mise à l’échelle empiriques.
Au lieu de taper toute cette formule, nous pouvons utiliser la fonction calculate_indices pour calculer l’EVI. calculate_indices nécessite trois entrées :
Le nom du jeu de données, par exemple « landsat_ds ».
Le nom de l’indice à calculer, par exemple
index='EVI'Le numéro de la collection Landsat, par exemple « collection=”c2”`` ».
c2 stands for “Collection 2”, which is the currently-available Landsat collection of data as named by its publishers, US Geological Survey.
Dans la cellule suivante, entrez le code suivant, puis exécutez-le pour calculer l’indice de végétation EVI pour ces données.
landsat_ds = calculate_indices(landsat_ds, index='EVI', collection='c2')
Ceci ajoute une variable appelée EVI à notre jeu de données landsat_ds.
Détecter les changements
Nous voulons déterminer ce qui a changé dans la végétation entre les moitiés plus anciennes et plus récentes des données.
Premièrement, nous diviserons les données de l’indice de végétation entre la moitié la plus ancienne et la moitié la plus récente. Les données qui ont été collectées dans la première moitié de notre période (2013 à 2015) iront dans la moitié plus ancienne, et les données collectées dans la seconde moitié (2016 à 2018) seront dans la nouvelle moitié.
La division est faite en utilisant sel() et slice().
sel()signifie « sélection » et nous indique que nous prenons une sélection de l’ensemble des données. Nous devons définir par quelle coordonnée nous allons sélectionner. Dans ce cas, nous allons utiliser la coordonnéetime.slice()spécifie quelle partie de la coordonnée nous prenons. Dans ce cas, nous voulons découper letime(temps) entre 2013 et 2015, puis entre 2016 et 2018. Rappelez-vous que nous avons nommé le point médian « time_baseline ».
Nous utilisons sel() et slice() pour créer deux nouveaux ensembles de données :
Baseline_sample: EVI de 2013 à 2015postbaseline_sample: EVI de 2016 à 2018
Pour ce faire, entrez le code suivant dans la cellule suivante.
baseline_sample = landsat_ds.EVI.sel(time=slice(time[0], time_baseline))
postbaseline_sample = landsat_ds.EVI.sel(time=slice(time_baseline, time[1]))
Ici, l’utilisation de time[0] nous donnera la première date que nous avons stockée dans la variable time ('2013-01-01'), et time[1] nous donnera la deuxième date que nous avons stockée dans la variable time ('2018-12-0'). En utilisant directement la variable time, nous nous assurons que le code fonctionnera si ces dates sont modifiées et que le notebook est réexécuté.
Note
Vérifiez soigneusement toutes vos paires ., ,, () et ' ' dans le code ci-dessus pour éviter de générer des erreurs.
Détecter les changements par pixel
Maintenant que nous avons nos ensembles de données «avant» et «après», nous pouvons les comparer pour le changement dans EVI. Pour ce faire, nous allons former un composite pour chaque moitié de l’ensemble de données. Ensuite, nous calculerons les différences de l’EVI moyen pour chaque pixel.
La méthode composite que nous utilisons est la moyenne (moyenne).
Dans la cellule suivante, entrez le code suivant, puis exécutez-le pour créer des composites moyens pour les deux périodes.
baseline_composite = baseline_sample.mean('time')
postbaseline_composite = postbaseline_sample.mean('time')
Maintenant, nous devons soustraire la moyenne composite de l’IVE de la première période, baseline_composite, de la moyenne composite de l’IVE de la deuxième période, postbaseline_composite. Ceci déterminera le changement de l’IVE entre les deux périodes.
Dans la cellule suivante, entrez le code suivant, puis exécutez-le pour déterminer la modification de l’indice de végétation.
diff_mean_composites = postbaseline_composite - baseline_composite
Dans la cellule suivante, entrez le code suivant, puis exécutez-le pour afficher la différence entre les composites moyens pour les périodes. Cela nous permettra de voir où l’indice de végétation a augmenté ou diminué et de combien.
plt.figure(figsize=(9, 8))
diff_mean_composites.plot.imshow(cmap='RdBu')
plt.title("Mean Composite Difference (Older to Newer)")
plt.show()
Votre intrigue doit ressembler à l’image ci-dessous.
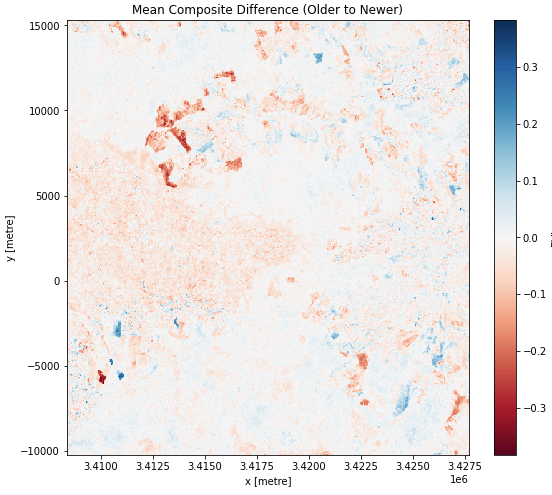
Interpréter l’intrigue
Dans le code ci-dessus, la couleur du tracé est définie à l’aide du paramètre cmap='RdBu' dans l’appel de fonction diff_mean_composites.plot.imshow(). Ici, RdBu correspond à une carte de couleurs rouge-bleu, les valeurs les plus faibles apparaissant en rouge, et les valeurs les plus élevées en bleu.
Les zones en bleu (changement positif) correspondent à une augmentation de la végétation telle que mesurée par l’EVI. Il y a plus de végétation dans ces zones dans l’échantillon 2016-2018 que dans l’échantillon 2013-2015.
Les zones en rouge (changement négatif) correspondent à une diminution de la végétation telle que mesurée par l’EVI. Il y a moins de végétation dans ces zones dans l’échantillon 2016-2018 que dans l’échantillon 2013-2015.
Quelles conclusions pouvez-vous tirer des changements du paysage à partir de cette intrigue? De quelles autres informations pourriez-vous avoir besoin pour vous aider à l’évaluer?
Conclusion
Félicitations ! Vous avez réalisé votre propre carnet de détection des changements de végétation. Il est comparable au « carnet de détection des changements de végétation de l’Environnement Sable » existant <https://docs.digitalearthafrica.org/en/latest/sandbox/notebooks/Real_world_examples/Vegetation_change_detection.html>`__. Le notebook existant peut sembler intimidant, mais il comprend beaucoup des étapes que vous venez de faire ! En plus de définir une scène “avant” et “après”, le notebook :
Trace des cartes en couleurs vraies (RVB) pour inspecter la zone d’intérêt.
Quantifie le changement à l’aide de tests statistiques (test t de Welch pour les zones de variance inégale).
Identifies statistically significant change
Un graphique de différence, comme celui que nous avons réalisé ci-dessus, est un bon moyen de commencer. Vous pourrez ensuite décider si vous avez besoin d’une analyse plus complexe ou non. Vous comprenez maintenant comment structurer une étude de cas complète - vous pouvez calculer un indice de bande pertinent et identifier les changements significatifs de cet indice dans le temps.
Activité optionnelle
Si vous êtes curieux de savoir comment fonctionne l’étude de cas existante, vous pouvez l’ouvrir et l’exécuter dans le bac à sable:
From the main Sandbox folder, open the Real_world_examples folder
Double-click the Vegetation_change_detection.ipynb notebook to open it
Le cahier a déjà été exécuté, vous pouvez donc le lire étape par étape. Cependant, vous pouvez trouver utile d’effacer les sorties et d’exécuter chaque cellule étape par étape pour voir comment elle fonctionne. Vous pouvez le faire en cliquant sur Kernel -> Restart Kernel and Clear All Outputs. Lorsqu’on vous demande si vous voulez redémarrer le noyau, cliquez sur Restart.
Il existe de nombreuses similitudes entre le carnet de notes que vous avez construit dans cette session et le carnet de notes existant de Sandbox. Prenez note de ce qui est similaire et de ce qui est différent, et passez un peu de temps à inspecter les différents codes. Si vous avez des questions sur le fonctionnement du notebook existant, veuillez les poser aux instructeurs lors d’une Session vivante.